MySQL 到达梦数据库(DM8)数据迁移同步:5分钟搞定
国产化替代大趋势下,MySQL 数据平滑迁移到达梦 DM8 是刚需。本文用 DataMover 带你走完 Docker 部署、数据源配置、任务创建、执行监控到结果验证的全流程。
说说这个场景
做过信创项目的人都知道——MySQL 的数据要迁到达梦,看着简单,真上手就不是那么回事了。
达梦的 SQL 语法和 MySQL 有差异,字段类型、自增主键、字符集都得处理。传统做法是:MySQL 导出 SQL → 手动改写达梦兼容语法 → 分批导入。一张表还好,几十上百张表的时候,光改 DDL 就能改到怀疑人生。
我之前试过用 DataX 做,但 DataX 没有 Web 界面,全靠 JSON 配,调试一次重启一次,效率实在上不去。
后来换了 DataMover,第一感受就是——这才是干这个活的工具。

DataMover 有哪几个功能对这个场景特别有用
先简单说几个关键能力,后面实操都能看到:
- 自动建表:MySQL 的
CREATE TABLE进来,DataMover 自动转换成达梦兼容的 DDL。字段类型、注释都在,不用手工改。 - 智能映射:同名字段自动匹配,命名不一致的手动一拖就行。
- 断点续传:任务跑到一半断了?重启接着跑,不重复不丢数据。
- 可视化 Web 界面:不用写 JSON,浏览器里勾选配置就能跑。
说白了,DataMover 帮我把最烦人的"DDL 转换 + 字段映射"这两件事自动做掉了。
安装部署
DataMover 有两种安装方式,一个命令行搞定。
Docker 一键部署(推荐)
Linux / macOS:
curl -fsSL https://down.datamover.cn/install.sh | bash
Windows PowerShell:
Set-ExecutionPolicy Bypass -Scope Process -Force; irm https://down.datamover.cn/install.ps1 | iex
脚本会自动检测 Docker 环境、下载压缩包、拉取镜像并启动所有容器。第一次启动需要 3-5 分钟做 MySQL 初始化和建表,耐心等一会儿就好。
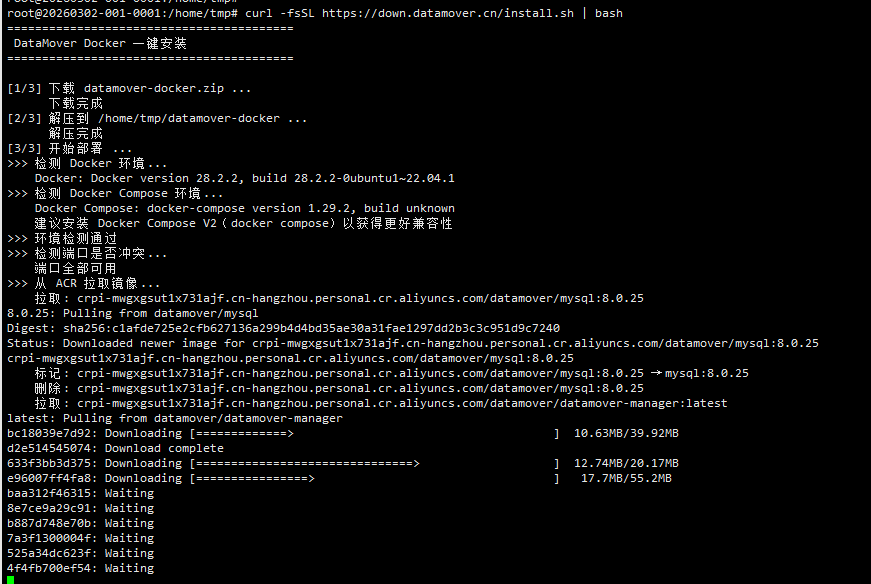
启动完成后访问 http://localhost:8000,用默认账号 admin / admin123 登录。

如果你希望先看下部署包的内容再动手,也可以从官网下载 datamover-docker.zip,解压后编辑 .env 文件改密码,然后执行 ./deploy.sh:
unzip datamover-docker.zip
cd datamover-docker
# 可选:修改 .env 中的数据库密码
./deploy.sh
原生安装包部署
不想用 Docker 的话,官网下载页也提供原生安装包,分 Linux、Windows、macOS 三个版本,解压后执行启动脚本就行。
Linux / macOS:
wget https://down.datamover.cn/datamover-latest.zip
unzip datamover-latest.zip
cd datamover
./bin/startup.sh
Windows:
# 下载 zip 包解压后
.\bin\startup.bat
启动后同样是 http://localhost:8000 访问,使用体验和 Docker 版完全一样。安装方式不同,使用起来没什么区别。具体步骤可以看官方文档。所有安装包在官网下载页都能找到。
不管哪种方式,结果是一样的——Manager 服务跑在 8000 端口,Worker 跑在 8011 端口。
登录后能看到数据源管理、任务管理、节点管理几个核心模块。每个页面都简洁,没什么花哨的。

配置数据源
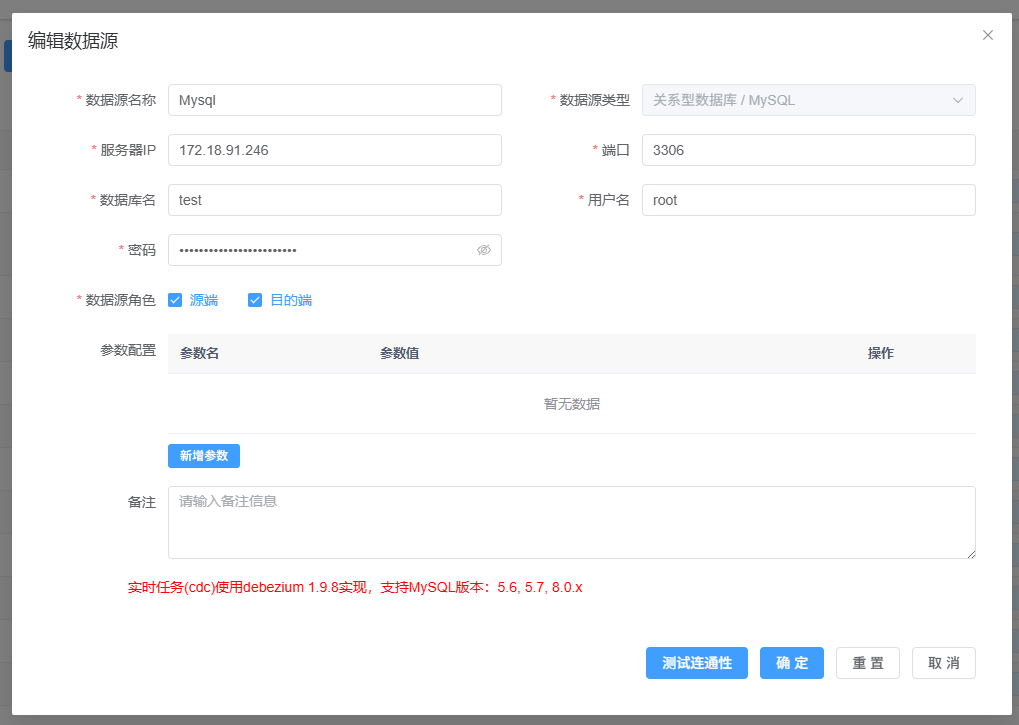
添加 MySQL 数据源
左侧导航进"数据源管理" → "新增数据源":
- 类型选择 MySQL
- 填上连接信息:主机、端口(3306)、库名、用户名、密码
- 点击"测试连接"验证
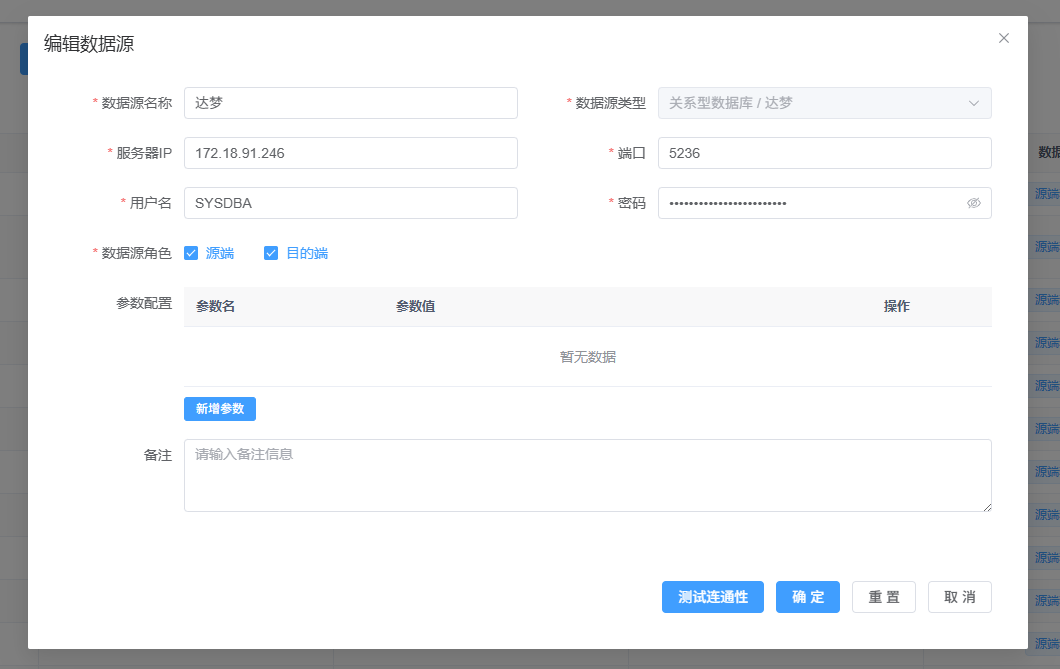
添加达梦数据源
达梦的配置稍微有一点需要注意。同样点"新增数据源":
- 类型选择 达梦(DM)
- 连接地址格式:
jdbc:dm://192.168.1.100:5236(默认端口 5236) - 填写达梦的数据库名、用户名、密码
- 测试连接
这里有个坑——达梦数据库的 JDBC 驱动版本和 DataMover 自带的版本一定要匹配。如果你用的达梦版本比较老(DM7),DataMover 能否兼容需要确认。本文以 DM8 为准,如果你用的是 DM7,建议先联系 DataMover 技术支持确认一下驱动版本。
创建同步任务
数据源配好之后,核心环节来了。
选择源和目标
点"新增任务":
- 基础信息:给任务起个名,比如"mysql_to_dameng_order"
- 选择源:选刚才配好的 MySQL 数据源
- 选择目标:选达梦数据源
表选择
源库的表列表会列出来,勾选你要迁移的表。我选了业务常用的几张表:orders、users、products、order_items。
选完后,DataMover 会自动检测目标库是否存在同名表。如果不存在,下一步会触发自动建表。
字段映射
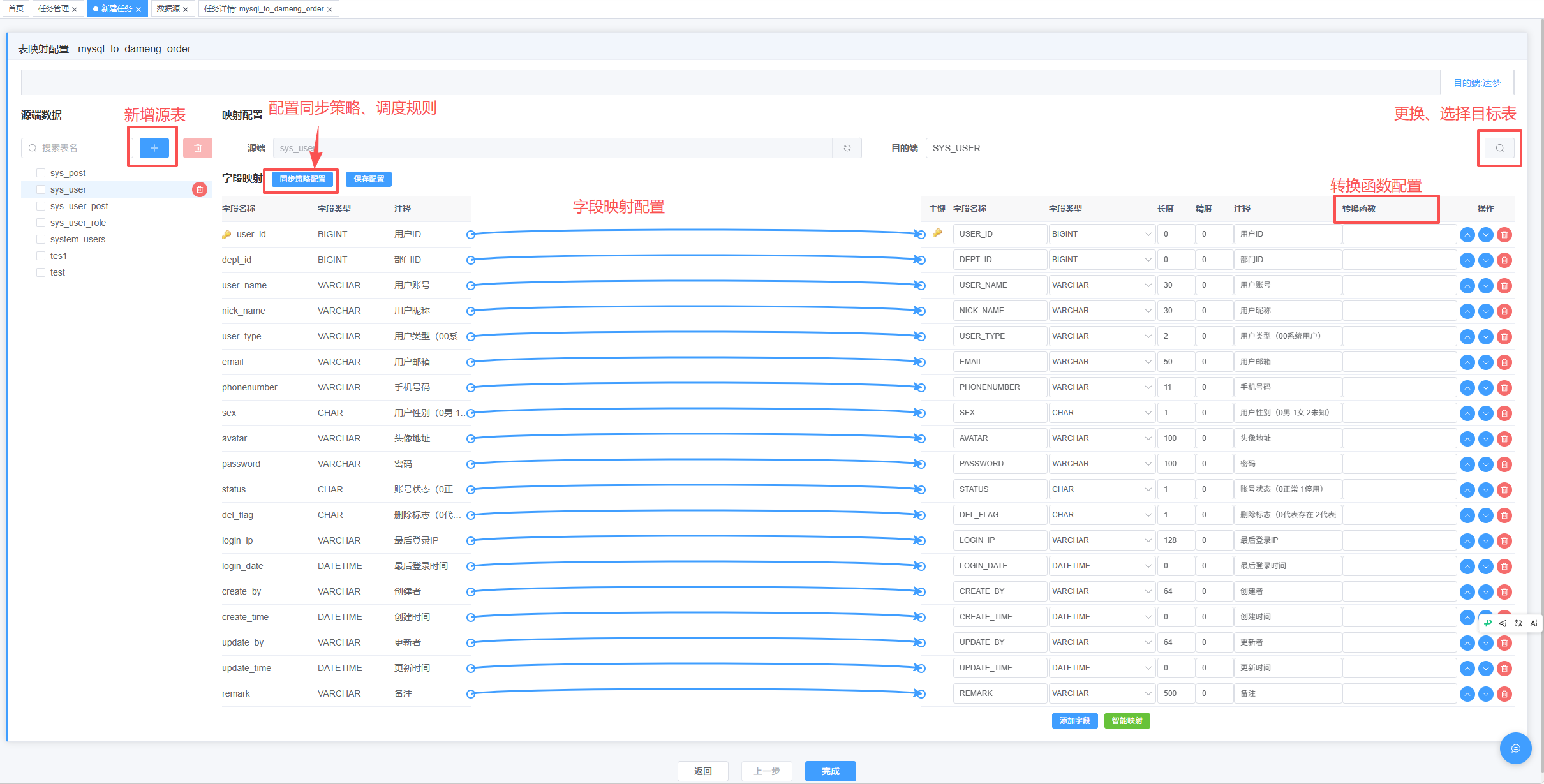
这是我最喜欢的一个环节——字段映射界面会把源表和目标表的字段左右对比展示。
同名字段(比如两边都有 id、name、created_at)会自动匹配上。命名不一样的手动拖一下就行。
自动建表
如果达梦库里没有这张表,DataMover 会显示"目标表不存在,将自动创建"。这一点在国产化迁移场景里太省事了——MySQL 的 AUTO_INCREMENT 会被转换成达梦的 IDENTITY,VARCHAR 长度、DATETIME 类型都会做对应转换。
我个人建议:正式迁之前先让 DataMover 自动建表,然后到达梦客户端看一眼 DDL,确认转换结果符合预期,再正式跑全量迁移。
同步模式
这里选全量同步,一次性把 MySQL 的所有数据搬到达梦。如果你后续还需要增量同步,可以选择"增量同步"或"CDC 实时同步"。免费版也支持 CDC,只是任务数、节点数和数据源范围按免费版规格限制。
执行与监控
配置完成后点"保存并启动"。任务开始跑之后,监控界面上能看到:
- 当前进度:已处理行数 / 总行数
- 吞吐量:每秒多少行
- 运行状态:运行中 / 已完成 / 异常
- 日志:每条同步记录的详细日志
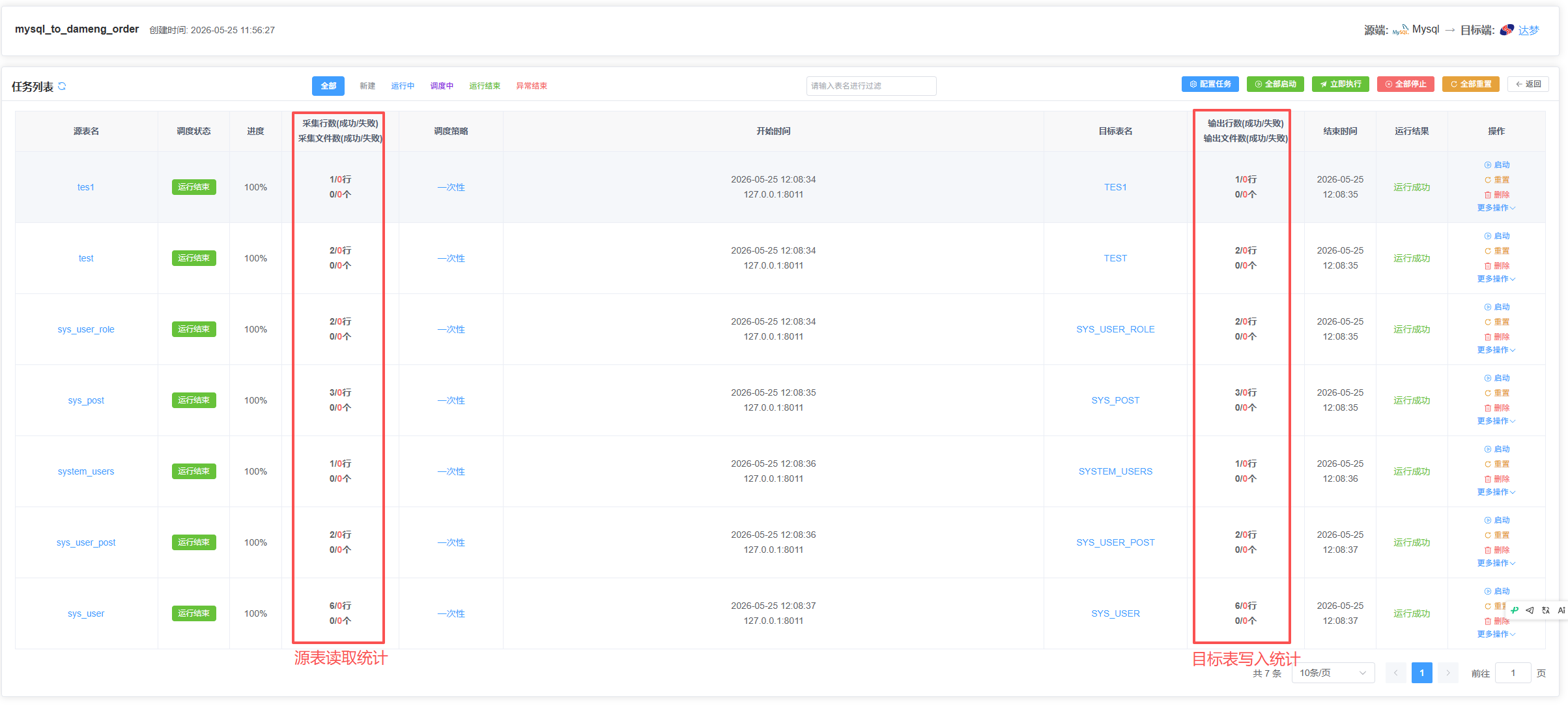
如果任务中途报错,DataMover 会显示具体的错误信息和 SQL 上下文。常见错误比如"字段类型不兼容"——在字段映射里改一下类型映射就好,不用重新配置整个任务。
结果验证
同步完后,我在达梦的查询工具里做了几项验证:
1. COUNT 校验
-- MySQL 源库
SELECT COUNT(*) FROM orders;
-- 返回:500000
-- 达梦目标库
SELECT COUNT(*) FROM orders;
-- 返回:500000
2. 抽样核对
取几条关键数据,对比字段值是否一致:
-- MySQL
SELECT * FROM orders WHERE id IN (1, 100, 10000, 500000);
-- 达梦
SELECT * FROM orders WHERE id IN (1, 100, 10000, 500000);
3. 表结构检查
看看自动建表的结果——字段名、类型、注释都对得上。
踩坑记录
做这个迁移的时候,我遇到了几个问题,写出来给你参考:
坑 1:达梦连接失败 — 端口不对
第一次添加达梦数据源时报连接超时。查了半天发现达梦默认端口不是 5236,安装的时候改成了 5237。这事看起来小,但排查花了我十几分钟。
坑 2:自增主键映射
MySQL 的 AUTO_INCREMENT 到达梦后变成了 IDENTITY,DataMover 的自动建表处理了这个转换,但如果你有业务逻辑依赖主键的自增值,需要在迁移前先跑一下达梦的序列,确保从正确值开始。
坑 3:字符集问题
源库 MySQL 是 utf8mb4,达梦默认字符集可能是 GBK。如果配置不对,中文数据入库后变成乱码。解决方式:到达梦的 JDBC 连接串上加参数 ?characterEncoding=UTF-8。
坑 4:大表超时
并发小表50 万行没问题,但如果几千万行多表并发执行,默认的 JVM 内存可能不够。Worker 容器的默认 JVM 配置是 2GB,大表场景建议调到 4GB 以上,在 .env 文件中加一行:
JAVA_OPTS=-Xms4g -Xmx4g
改完后重新部署:./deploy.sh,脚本会自动拉最新配置重启服务。
总结
说白了这个场景的核心就是:MySQL 的数据要搬到达梦,中间不能丢、不能错、能断点续传。DataMover 干这事确实省心——Docker 拉起即用,Web 界面配一配就跑起来了,自动建表和智能映射帮我把最烦人的 DDL 转换和字段对齐做掉了。

相关同步方案
除了MySQL到达梦数据库迁移同步,DataMover还支持以下场景:
常见问题解答
MySQL到达梦数据库迁移支持增量同步吗?
支持。DataMover提供全量迁移、基于时间戳的增量同步和CDC实时同步三种模式,免费版也支持CDC。
MySQL到达梦的自动建表能处理哪些DDL差异?
自动处理 AUTO_INCREMENT→IDENTITY、VARCHAR长度映射、DATETIME类型转换、注释同步等常见差异。建议正式迁移前先检查自动生成的DDL。
Docker部署DataMover迁移MySQL到达梦需要什么配置?
2核4GB即可流畅运行。社区版永久免费,支持3个同步任务和17种数据源,不限制数据量。
数据迁移过程中源库MySQL会有影响吗?
全量迁移采用无锁读取方式,对源库性能影响极小。CDC模式基于binlog解析,也不影响源库正常运行。
开始配置 DataMover 同步任务
下载 DataMover 后,可按文档完成数据源、表映射、同步策略、任务启动和执行结果校验。